
You spent hours writing a post, published it, and then watched a thinner, less thorough competitor sit comfortably in the top three results while your page collects dust on page four. It’s one of the most frustrating experiences in SEO, and it happens because most site owners have never seen a clear explanation of how Google’s search algorithm decides rankings. The algorithm isn’t a single mysterious score, it’s a layered pipeline with distinct stages, and each stage filters what makes it to the top.
This guide walks you through that pipeline from the moment Google’s crawler discovers your URL to the instant a ranked result appears on screen. Understanding how Google’s search algorithm decides rankings is the foundation behind every guide we publish at AISEO Round Table, including our hands-on reviews of tools that help you act on these signals without an agency budget. By the end, you’ll know what Google actually weighs and, more importantly, where to focus your energy first.
How Google gets to your page before any ranking happens
Before a single ranking signal is evaluated, Google has to find your page, fetch it, and decide whether it belongs in the index at all. Think of Googlebot as a librarian who reads every book on the web, files a summary card for each one, and then pulls the right cards when someone asks a question. No card on file means no chance of appearing in search results, regardless of how good the content is.
What Googlebot actually does when it visits a page
Googlebot discovers URLs through links, sitemaps, and other discovery signals, then schedules each URL for a fetch. Crawl budget matters here, Google won’t crawl every page on your site with equal frequency, so strong internal linking helps important pages get found and recrawled more often. If a key page has no internal links pointing to it, Googlebot may not prioritize it, and that’s a problem that has nothing to do with content quality. For a deeper look at building a crawl-friendly structure, check out our How Search Engines Work: Crawling, Indexing, Ranking.
From crawl to index: what Google stores and why it matters
Crawling and indexing are two separate steps. Google fetches the page, processes its text, structured data, and links, renders JavaScript if needed, and then decides whether the page is eligible for the index. Pages can be crawled but still excluded if they carry a noindex tag, are flagged as duplicate, or don’t clear Google’s quality threshold. A page that isn’t indexed is invisible to every ranking system that follows, which means content quality becomes irrelevant until that problem is resolved.
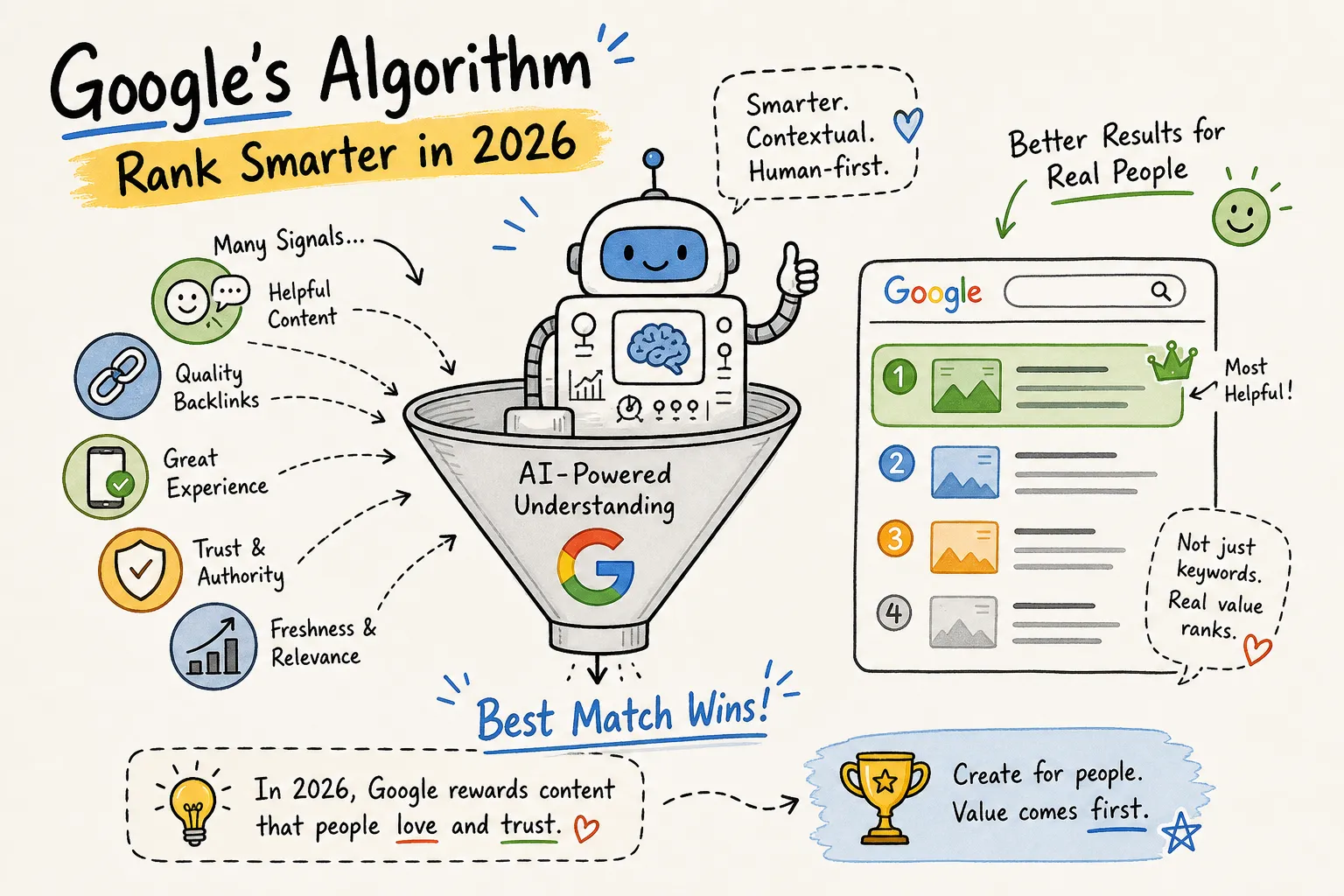
How Google’s search algorithm decides rankings: the key signals
Once a page is in the index, Google’s ranking systems evaluate it against every query it could potentially answer. Not all signals carry equal weight, and Google’s own documentation gives us a rough priority order. Understanding that hierarchy keeps you from obsessing over low-impact tweaks while the factors that actually move results go unaddressed. For an accessible summary of the broader Google ranking factors, there are several high-quality roundups that synthesize research and official guidance.
Relevance and content quality: the two signals Google names first
Google’s ranking systems documentation explicitly names content relevance and content quality as the top considerations. Systems like BERT, RankBrain, and MUM, described in Google’s language understanding overview, interpret query meaning at a deep conceptual level, matching intent rather than just matching words. That’s why satisfying what someone actually wants from a search beats stuffing a target phrase into every paragraph. A page that completely answers the question wins over a page that mechanically repeats a keyword.
Links and authority: still important, still less explicit
PageRank remains part of Google’s core ranking systems, functioning as a link-analysis signal that estimates page importance based on the structure of inbound links. Links from authoritative, relevant pages pass more value than links from weaker sources, and the signal compounds across the web graph. Google is less explicit about this in public-facing documentation than it is about content quality, but ranking studies consistently show strong real-world impact. For a small site, earning even a handful of links from trusted sources in your niche can carry more weight than most on-page tweaks, though the relative impact depends on the query, the niche, and how well your technical foundation is already performing. For a technical explainer of how PageRank functions conceptually, see this PageRank overview.
Freshness: when recency actually matters and when it doesn’t
Google runs a “query deserves freshness” system that surfaces newer content for searches where recency is expected, news, recent events, or rapidly changing topics. For evergreen content like a tutorial on internal linking or a guide to meta tags, freshness is far less decisive. The practical rule: if the query is one where someone would be disappointed by a two-year-old answer, update your page regularly. If it’s a stable topic, put that time into content depth instead.
E-E-A-T: Google’s quality lens, not a single ranking score
E-E-A-T is one of the most misunderstood concepts in SEO. Many beginners treat it as a measurable score that Google calculates and assigns to a page. That’s not how it works. E-E-A-T is a quality evaluation framework Google uses to assess whether content is likely to be helpful and reliable, with varying levels of scrutiny depending on what’s being searched. For further reading on how E-A-T and related signals are interpreted in practice, see this E‑A‑T resource, and our own perspective in Google Says Ranking Systems Reward Content Made for Humans.
What each letter means and why trust sits above the rest
Experience refers to firsthand knowledge of the topic. Expertise reflects demonstrated knowledge and skill. Authoritativeness speaks to how the broader web perceives the source. Trustworthiness is the anchor: Google’s Search Quality Rater Guidelines explicitly frame trust as the most important of the four, with experience, expertise, and authority all feeding into it. A page can show strong expertise but still fail the trust test if the site has no transparent authorship, intrusive ads, or unclear sourcing.
How E-E-A-T expectations shift depending on what someone searches
For a general informational query, a well-written, clearly sourced page can perform well without credentialed authorship. For health, finance, safety, and other YMYL (Your Money or Your Life) topics, Google applies much higher scrutiny because the cost of a bad answer is significant. A blogger covering a YMYL topic needs stronger trust signals, named authors with verifiable credentials, transparent sourcing, and a clean site reputation, to compete seriously. For non-YMYL content, demonstrating genuine experience through specific details and real examples is usually enough to clear the bar.
Page experience and technical signals that influence where you land
Technical SEO isn’t a separate discipline from content strategy. Google’s ranking systems evaluate page-level usability alongside content quality in the same process, and a page that loads slowly, shifts layout unpredictably, or feels broken on a phone is sending signals through real user data that feed directly into ranking decisions.
Core Web Vitals explained without the jargon
Google measures three Core Web Vitals using real user data at the 75th percentile of page loads. LCP (Largest Contentful Paint) measures how fast the main content loads, with a “good” threshold of 2.5 seconds or less. INP (Interaction to Next Paint) measures responsiveness to user input, with a passing score of 200 milliseconds or less. CLS (Cumulative Layout Shift) measures visual stability, and a score of 0.1 or less is considered good. For the official definitions and guidance, review the Core Web Vitals documentation.
Of the three, LCP tends to be the most consequential for perceived load performance on most sites, slow-loading pages frustrate users and underperform in competitive SERPs. That said, which metric needs the most attention varies by site type and user interaction patterns, so check your Core Web Vitals report in Search Console rather than assuming a single fix applies everywhere.
Mobile usability and site architecture as ranking foundations
Google uses the mobile version of your site as the primary version for indexing and ranking. If your layout breaks on a phone, that’s a ranking liability, not just a UX inconvenience. Clean URL structure and logical internal linking help Googlebot discover pages efficiently and help users navigate without friction. These architectural decisions compound over time because they affect crawl coverage, link equity distribution, and how easily a visitor finds what they need, all factors that tie back to how Google’s search algorithm decides rankings for your pages.
Key ranking factors for Google: a prioritized action plan
Understanding Google’s ranking systems is useful only if it changes how you allocate your time. Based on what Google’s own documentation actually says, there’s a consistent priority order, and following it prevents the common mistake of optimizing metadata on a page that Google can barely load on mobile.
The high-impact fixes most site owners skip
Start with page speed and Core Web Vitals. Compress images, switch to modern formats like WebP, reduce render-blocking scripts, and add a CDN if your host doesn’t already provide one. Google’s PageSpeed Insights documentation walks through each of these fixes in detail. Once your technical foundation is solid, audit your internal linking structure. Important pages with few or no internal links pointing to them are underperforming because they’re not getting the crawl attention or link equity they need. Build that foundation before touching anything else.
Content alignment and authority building: the longer game
After the technical layer is stable, revisit your existing pages and ask whether each one genuinely satisfies the search intent better than the current top-ranking result. Often the gap isn’t keyword coverage, it’s depth, specificity, or a missing format that searchers expect.
On the authority side, create genuinely useful assets, original data, practical tools, or detailed guides, and pursue links from relevant sources in your niche rather than chasing volume. Once those fundamentals are in place, refine titles, headings, and schema markup to improve click-through rates and content presentation in search results.
How to monitor the signals that matter most for your site
Knowing the signals is one thing; tracking whether your site is moving in the right direction is another. Two tools cover the essentials at any budget level.
Using Google Search Console to catch ranking problems early
Google Search Console is free and gives you direct feedback from Google about how it currently sees your site. The Performance report shows which queries drive impressions and clicks, and where average position is trending. The Coverage report flags pages that are crawled but not indexed, critical for catching thin-content or technical exclusion issues early. The Core Web Vitals report, documented in Google’s Search Console help center, shows real-user data segmented by mobile and desktop so you can prioritize speed fixes based on actual performance rather than guesswork. Check impressions, clicks, average position, and Core Web Vitals percentiles on a regular cadence, monthly at minimum, weekly if you’re actively publishing or making changes.
Tracking rankings and responding to changes
For rank tracking, SERP analysis, and backlink monitoring, a dedicated SEO tool rounds out what Search Console can’t show you. At AISEO Round Table, we’ve used Mangools for this layer, its KWFinder feature shows keyword difficulty and search volume so you can assess whether a page is targeting terms you can realistically compete for, and SERPChecker breaks down exactly who’s ranking and why. That said, tools like Ahrefs, Semrush, and Moz cover similar ground, and the best choice depends on your budget and workflow. What matters is picking one and using it consistently. Tracking these data points regularly is what separates sites that improve steadily from sites that publish and hope.
The ranking pipeline, start to finish
Google’s search algorithm isn’t a black box, and it isn’t a single score applied uniformly to every query. It’s a layered pipeline: crawl accessibility sets the floor, indexing quality sets the ceiling, and then ranking systems weigh relevance, content quality, links, page experience, and E-E-A-T in proportions that shift depending on what someone is searching for.
The sequence Google’s own documentation points toward is consistent: fix the technical foundation first, align your content with search intent more precisely than your competitors do, build real authority through links that reflect genuine usefulness, and monitor your signals in Search Console and a rank-tracking tool so you can catch problems before they compound. That’s how Google’s search algorithm decides rankings, and understanding each layer gives you a clear lever to pull instead of guessing.
That sequence won’t produce overnight rankings, but it builds the kind of durable visibility that holds up through algorithm updates. For tool-specific guides, step-by-step workflows, and ranking strategy breakdowns built on exactly this foundation, The Ultimate Guide to SEO: Rank Higher in 2025 at AISEO Round Table has you covered.


